
Farasa project has taken place within the Arabic Language Technology Group at Qatar Computing Research Institute (QCRI). I worked mainly to build a word segmentation and a POS tagger for dialectal Arabic.
The main theme of Farasa is to be fast, accurate and reliable tool to process Modern Standard Arabic (MSA) and its different dialects. Therefore, I have heavily depended on statistical approaches to build the different modules of Farasa.
Word Segmentation
I first began to tackle each dialect separately. Starting with Egyptian dialect, I have to deal with the following challenges:
- scarcity of annotated data, and
- Lack of spelling standard (dialectal Arabic is usually spoken and used in informal communications).
I have used a dataset collected originally for the task dialect identification and manually annotated
myself with segmentation
information. The dataset contains 350 tweets with more than 8000 words including 3000 unique words.The
tweets
have much dialectal content covering most of dialectal Egyptian phonological, morphological, and
syntactic phenomena.
I have built a dialectal Egyptian segmentater that utilizes Bidirectional Long-Short-Term-Memory
(BiLSTM)
that is trained on limited dialectal data. The approach was motivated by the scarcity of
dialectal tools and resources. The main contribution is that we build a segmenter
of dialectal Egyptian using limited data without the need for specialized lexical resources or
deep linguistic knowledge that rivals state-of-the-art tools.
The lack of lexical and linguistic resources have derived me to consider the Arabic word
segmentation as
a character-based sequence classification problem and to use 200-dimensional pre-trained
character
embeddings to initialize the lookup table. Each character is labeled as one of the five labels
B,M,E,S,WB that designate the segmentation decision boundary. B, M, E,WB represent Beginning,
Middle, End of a multi-character seg-ent, Single character segment, and Word Boundary
respectively.
The results show that for this small testset BiLSTM-CRF (92.65%) performs better than MADAMIRA

(92.47%) by only 0.18% which is not statistically significant. The advantage of my system is that, unlike MADAMIRA which relies on a hand-crafted lexicon, our system generalizes well on unseen data. To
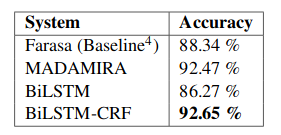
illustrate this point, the test set has 1,449 words, and 586 of them (40%)are not seen in the
training set.
This shows how well the system is robust with OOV words.
Extending for more dialects (Levantine, Moroccan, Gulf, and MSA)
Following the same approach, I have trained 3 models with tweets written in 3 other dialects, namely Levantine, Moroccan, and Gulf. In addition to the three dialects I also trained an extra model for MSA. This time I had compared the LSTM model for each dialect to an SVM model that is trained on the following features:
- Conditional probability that a leading char sequence is a prefix
- CP that a trailing char sequence is a suffix
- probability of the prefix given the suffix
- probability of the suffix given the prefix
- unigram probability of the stem
- unigram probability of the stem with first suffix
- whether a valid stem template can be obtained from the stem
- whether the stem that has no trailing suffixes appears in a gazetteer of person and location names
- whether the stem is a function word
- whether the stem appears in the AraComLex Arabic Lexicon
- length difference from the average stem length
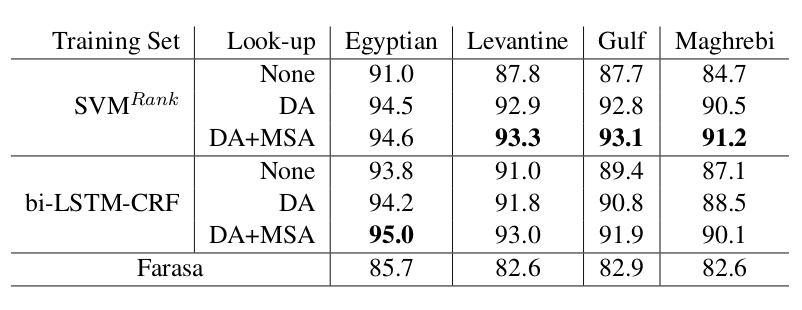
The above table reports on the results for both segmentation approaches and in combination of using
different lookup schemes. As the results clearly shows, using an MSA segmenter yields suboptimal results
for dialects. Also, when no lookup is used, the bi-LSTM-CRF sequence labeler performs better than the
SVM ranker for all dialects. However, using lookup leads to greater improvements for the SVM approach
leading to the best results for Levantine, Gulf, and Maghrebi and slightly lower results for Egyptian.
Further, SVMRank seemed to have benefited more from the DA lookup, while bi-LSTM-CRF
benefited more
from the MSA lookup.
As for Egyptian segmentation, we suspected that it performed better for both approaches than the
segmentation for the other dialects, because the percentage of test words that appear in the training
set was greater for Egyptian.
Learning from Relatives
I have observed that there are shared pan-dialectal linguistic phenomena that allow computational models for dialects to learn from each other. Accordingly, I built a unified segmentation model where the training data for different dialects are combined and a single model is trained.
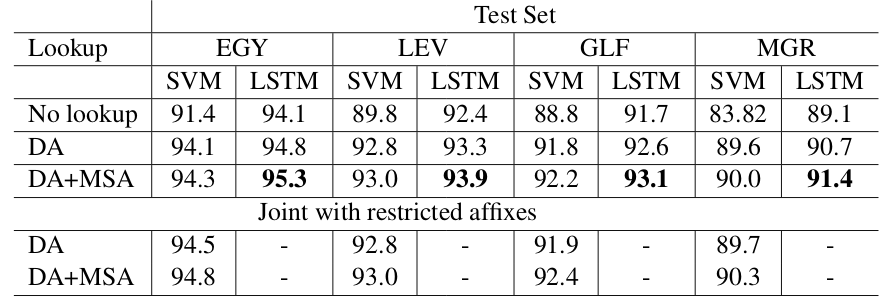
The results show improvements for all dialects, but aside for EGY, the improvements do not lead to better results than those for single dialect models. Conversely, the bi-LSTM-CRF joint model with DA+MSA lookup beats every other experimental setup that we tested, leading to the best segmentation results for all dialects, without doing dialect identification. This may indicate that bi-LSTM-CRF benefited from cross-dialect data in improving segmentation for individual dialects.
Publications
Kareem Darwish, Hamdy Mubarak, Mohamed Eldesouki , Ahmed Abdelali, Younes Samih, Randah Alharbi, Mohammed Attia, Walid Magdy, and Laura Kallmeyer, (2018), Multi-Dialect Arabic POS Tagging: A CRF Approach , In the 11th edition of the Language Resources and Evaluation Conference (LREC), 7-12 May 2018, Miyazaki (Japan).
Younes Samih, Mohamed Eldesouki , Mohammed Attia,Kareem Darwish, Ahmed Abdelali, Hamdy Mubarak and Laura Kallmeyer, (2017), Learning from Relatives: Unified Dialectal Arabic Segmentation . In Proceedings of the 21st Conference on Computational Natural Language Learning (CoNLL 2017), Vancouver, Canada, 432-441.
Mohamed Eldesouki , Younes Samih, Ahmed Abdelali, Mohammed Attia, Hamdy Mubarak, Kareem Darwish and Kallmeyer Laura, (2017), Arabic Multi-Dialect Segmentation: bi-LSTM-CRF vs. SVM , http://arxiv.org/abs/1708.05891
Younes Samih, Mohammed Attia, Mohamed Eldesouki , Ahmed Abdelali, Hamdy Mubarak, Laura Kallmeyer and Kareem Darwish, (2017), A Neural Architecture for Dialectal Arabic Segmentation . In Proceedings of The 3rd Arabic Natural Language Processing Workshop (WANLP-2017) co-located with EACL 2017, Valencia, Spain, pages 46-54.