
At Qatar Computing Research Institute (QCRI), I have worked in collaboration with MIT CSAIL on the DialectID project that aims to automatic dialect identification in Arabic Broadcast Speech. Arabic Dialect Identification (ADI) is similar to the more general problem of Language Identification (LID) except that it is more challenging than LID because of the small and subtle differences between the various dialects of the same language. I worked with Dr. Ahmed Ali and Dr. James Glass to tackle the problem of classifying a given utterance into one of five dialects spoken in the Arab world namely, Egyptian dialect, Levantine dialect, Gulf dialect, North African (Tunisian, Moroccan, Algerian, and Lybian) dialect, or Modern standard Arabic (MSA).
Our best results for ADI gives us an accuracy of 78% overall accuracy across the five dialects using the 2017 Multi-Genre Broadcast challenge (MGB-3) data. In order to achieve a robust dialect identification, we explored using Siamese neural network models to learn similarity and dissimilarities among Arabic dialects, as well as i-vector post-processing to adapt domain mismatches. Both acoustic and linguistic features were used.
The Live Demo
My contribution to the project was mainly engineering resulting on a live identification system for the Arabic speech. I deployed two models, one that depends on lexical features and the second trained on only acoustic features. The system is capable to scale to thousands of parallel users. I used Kaldi, the popular Speech Recognition system, to produce the transcriptions of the utterances.
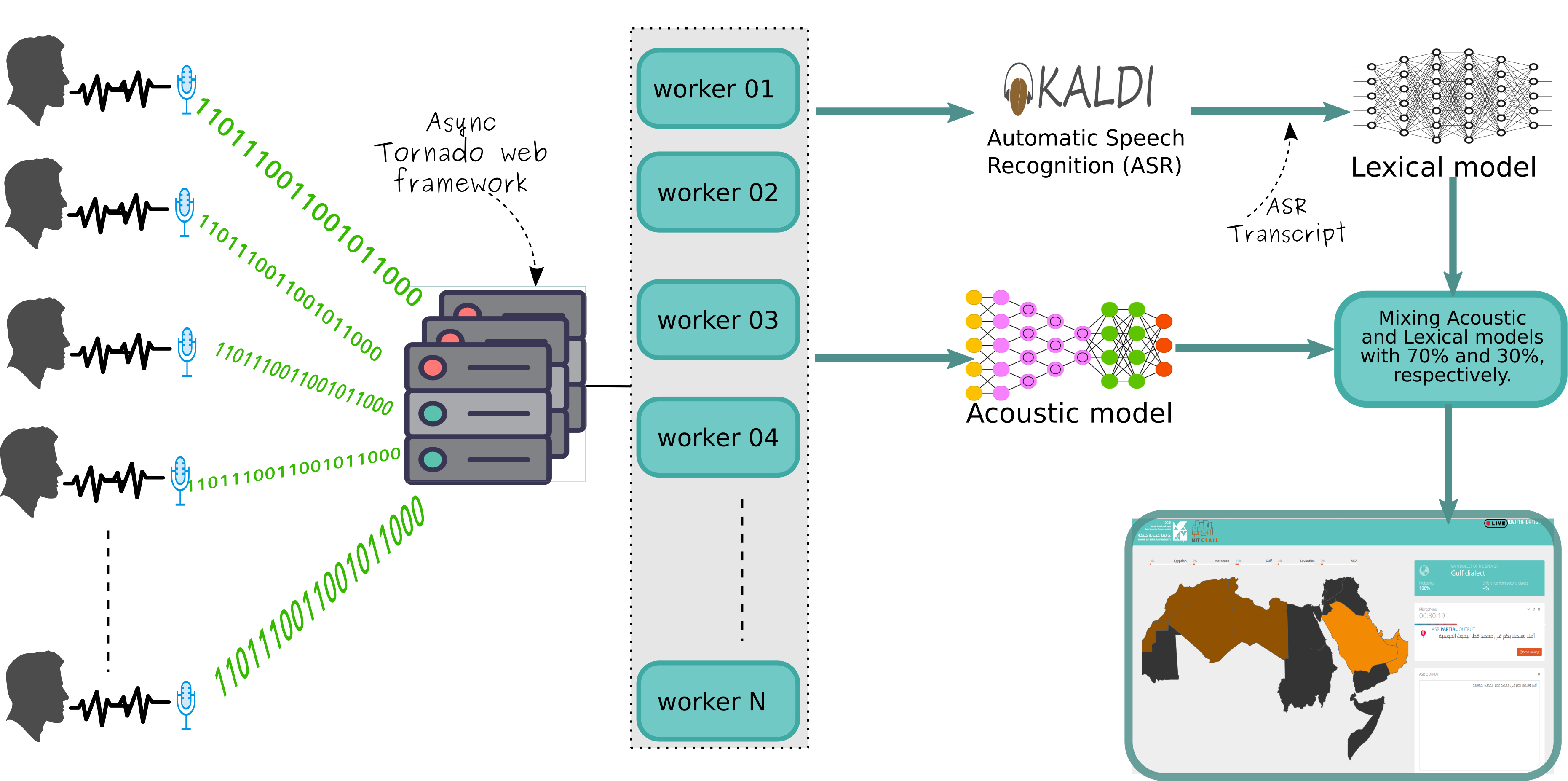
As user press the start button, the DialectID system keep receiving raw audio data from the speaker with no action taken. The system triggers the identification process only when Kaldi manages to produce transcription. The transcription is then used to generate the lexical features. Meanwhile, the resulting raw audio data is used to produce the acoustic features. Both of the features are then sent to models for identification and the result is sent back to the user. Each feature set
is then passed to the right model resulting on probabilities of the dialects. of the features are then sent to models for identification and the result is sent back to the user. Each feature set is then passed to the right model resulting on probabilities of the dialects.