
The project started in 2007 mainly to be a plug-in of Arabic language text analysis for the Tayait search engine (yajeel.com). TAPS is able to do tokenization, segmentation, normalization, morphological analyses, named-entity recognition, spellcheck error detection & correction, auto-completion, and text summarization.

I worked on TAPS project from May 2013 until September 2014 (1 year and half) while I was a Senior Software Engineer in collaboration with Dr. Ossam Emam at Taya IT company. I built the named-entity recognition and the spellcheck error detection & correction, and auto-completion. The following sections briefly discuss my work.
Named Entity Recognition
The aim was to recognise three type of named-entities; namely person names, location names and
organization names. I have used an inhouse data set that has been collected and annotated with
the three
types of the named-entities. The data set contains more than 3 million Arabic words collected
from news
articles crawled from more than 150 news websites spanning many genre such as politics, sports,
economy,
health & beauty, that are both local and international and that include original Arabic names or
names
transliterated into Arabic.
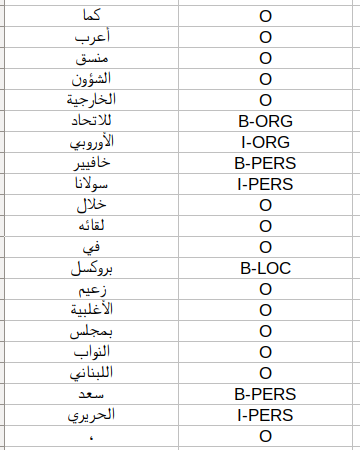
The same annotation schema of Benajiba had been used to annotate the inhouse data set using 9
tags; namely, B-PERS, I-PERS, B-LOC, I-LOC, B-ORG, I-ORG, B-MISC, I-MISC, O. B- means beginning
of Name and I- inside of a name.
The research focused on selecting the right features for use as an input to a discriminative classifier. We compared between two models; namely, Conditional Random Field (CRF) and Maximum Entropy approach. The following are the list of features that have been used in training the model:
- The word itself (no normalization or stemming),
- 6bi, 6tri and 6quad; characters of each word have been used (3 from the beginning and 3 from the end of the word),
- Part-Of-Speech,
- Gazetteers (Person names, Locations, Organization names),
- Has a prefixes: [f, w, l, b, k, Al, s] transliterated using buckwalter),
- Previous word,
- next word,
- POS of previous word,
- POS of next word,
- and finally, word bigram.
For evaluation, I splitted the the 3M word inhouse data set into 80% training and 20% testing for 5-folds cross validation.
For the seek of comparing our system with others, we have also used for further evaluation a well-known benchmark data set called ANERsys that has been used by many researchers to evaluate their NER systems.
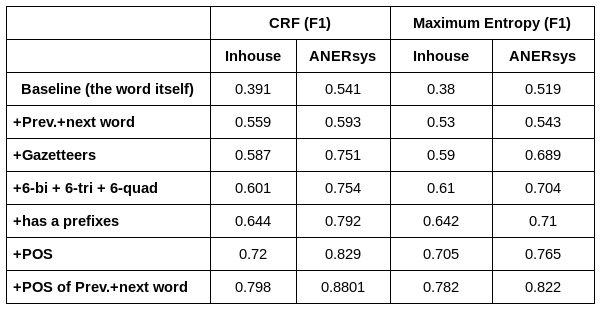
The above table reports on the results for the different features used. The features are added in accumulative way such that the feature of one is add to all previous features.